アナリティクス 2.0 の概要
目次
- Procore アナリティクス クラウド コネクタ
- セットアップの開始
- データ接続方法の選択
- Power BI Desktop に接続する
- Python (SSIS) を使用した SQL Server への接続
- Python ライブラリを使用して SQL Server に接続する
- Python Spark を使用して SQL Server に接続する
- Azure Functions を使用して ADLS に接続する
- Python を使用して ADLS に接続する
- Spark を使用した ADLS への接続
- Data Factory を使用して Fabric Lakehouse に接続する
- Fabric ノートブックを使用した Fabric Lakehouse への接続
- Azure Functions を使用して SQL Server に接続する
- Data Factory を使用した SQL Server への接続
- Fabric Notebook を使用した SQL Server への接続
- Databricks に接続する
- Pythonを使用したSnowflakeへの接続
- Python を使用して Amazon S3 に接続する
- 独自の接続を構築する
- BigQuery に接続する
- Exponam を使用して Microsoft Excel に接続する
Procore アナリティクス クラウド コネクタ
パートナーに関する考慮事項
権限の確認
データ アクセス認証情報の生成
Procore データへのアクセスを開始するには、データ アクセス認証情報を生成するための 2 つのオプションがあります: Databricks 直接接続方法またはデルタ共有トークン方法。アクセス トークンは、データにアクセスするために該当するデータ コネクタに入力する数字の文字列です。
検討事項
- 会社の Procore アカウントの会社レベルで分析ツールを有効にする必要があります。
- 既定では、すべての会社管理者は、ディレクトリ内の Analytics に対する「管理者」レベルのアクセス権を持っています。
- アナリティクス ツールへの「管理者」レベルのアクセス権を持つユーザーは、追加のユーザーにアナリティクス ツールへのアクセス権を付与できます。
- ユーザーがアクセス トークンを生成するには、分析ツールに対する「管理者」レベルのアクセス権が必要です。
ステップ
- Procore にログインします。
- ナビゲーションバーの右上にある [ Account & Profile (アカウントとプロファイル)] アイコンをクリックします。

- [ マイ プロファイル設定] をクリックします。
- [ Analytics との接続の選択] には、認証情報を生成するための 2 つのオプションがあります。
- Databricks は直接接続するか、Delta Share を使用して個人用アクセス トークンを生成します。
- Databricks 直接接続方法の Databricks 共有識別子 を入力し、 [ 接続] をクリックします。詳細については、「 Procore データを Databricks ワークスペースに接続する 」を参照してください。
- トークンの方法として、 [ Delta Share Token](デルタ共有トークン) を選択します。
- 必ず有効期限を選択してください。
- 「 トークンの生成」をクリックします。
大事な!Procore はユーザーのトークンを保存しないため、将来の参照のためにトークンをコピーして保存することをお勧めします。 - ベアラー トークン、共有名、デルタ共有サーバーの URL、および共有資格情報のバージョンを使用して、データへのアクセスと統合を開始します。

- 目的のデータ接続方法に基づいてデータを接続するための次のステップについては、スタートガイドの追加セクションを参照してください。
注
- トークンは 1 時間後に消えるか、ページから移動すると消えます。新しいトークンを生成するには、ステップ 1 に戻ります。
- データが表示されるまでに最大 24 時間かかる場合があります。
- この処理時間中にトークンを再生成すると、トークンに問題が発生する可能性があるため、トークンを再生成しないでください。
Power BI にレポートをアップロードする (該当する場合)
- 会社の [ツール] メニューから [アナリティクス] に移動します。
- 「はじめに 」セクションに移動します。
- [ Power BI ファイル] で、使用可能な Power BI レポートを選択してダウンロードします。
- Power BI ログイン認証情報を使用して Power BI サービス にログインします。
- 会社のアナリティクス レポートを保存するワークスペースを作成します。詳細については 、Microsoft の Power BI サポート ドキュメント を参照してください。
ノート: ライセンス要件が適用される場合があります。 - ワークスペースで、[ アップロード] をクリックします。
- 次に、[ 参照]をクリックします。
- コンピューター上の場所からレポート ファイルを選択し、[開く] をクリックします。
- ファイルをアップロードしたら、 [フィルター] をクリックし、 [セマンティック モデル] を選択します。
- レポート名の行の上にカーソルを置き、垂直の 省略記号
 アイコンをクリックします。
アイコンをクリックします。 - [設定] をクリックします。
- 設定ページで、[データ ソースの資格情報] をクリックし、[資格情報の編集] をクリックします。
- 表示される「[レポート名] の構成」ウィンドウで、次の手順を実行します。
- 認証方法: 「キー」を選択します。
- アカウント キー: Procore のトークン生成ページから受け取ったトークンを入力します。
- このデータ ソースのプライバシー レベル設定: プライバシー レベルを選択します。「非公開」または「組織」を選択することをお勧めします。見る Microsoft の Power BI サポート ドキュメント プライバシー レベルの詳細については、を参照してください。
- [サインイン] をクリックします。
- [R efresh] をクリックし、次の操作を行います。
- タイム ゾーン: スケジュールされたデータ更新に使用するタイム ゾーンを選択します。
- [ 更新スケジュールの構成] で、トグルを [オン] の位置にします。
- 更新頻度: [毎日] を選択します。
- [時間]: [別の時間を追加] をクリックし、午前 7:00 を選択します。
手記:更新時間は最大 8 回まで追加できます。 - オプション:
- [データセットの所有者に更新失敗通知を送信する] チェックボックスをオンにして、更新失敗通知を送信します。
- システムが更新失敗通知を送信する他の同僚の電子メール アドレスを入力します。
- [適用] をクリックします。
- 設定が正しく構成され、レポートのデータが適切に更新されることを確認するには、[フィルター処理してセマンティック モデルを選択] ページに戻り、次の手順を実行します。
- レポート名の行の上にカーソルを置き、円形の矢印アイコンをクリックしてデータを手動で更新します。
- 「更新済み」列をチェックして、警告
 アイコンがあるかどうかを確認します。
アイコンがあるかどうかを確認します。
- 警告アイコンが表示されない場合、レポートのデータは正常に更新されています。
- 警告アイコンが表示された場合は、エラーが発生しています。 警告 アイコンをクリックすると、エラーの詳細が表示されます。
- Power BI サービスによって自動的に作成された空のダッシュボードを削除するには、次の手順を実行します。
- ダッシュボードの名前の行の上にカーソルを置きます。省略記号
 アイコンをクリックし、[削除] をクリックします。
アイコンをクリックし、[削除] をクリックします。
- ダッシュボードの名前の行の上にカーソルを置きます。省略記号
- レポートが正しく表示されることを確認するには、[すべて] または [コンテンツ] ページに移動し、レポートの名前をクリックして Power BI サービスでレポートを表示します。
ヒント
「タイプ」列を参照して、別のアセットではなくレポートをクリックしてください。
- Power BI 内で、Analytics レポート ファイルごとに上記の手順を繰り返します。
Power BI Desktop に接続する
Python (SSIS) を使用した SQL Server への接続
概要
Analytics Cloud Connect Access ツールは、Procore から MS SQL Server へのデータ転送の構成と管理に役立つコマンドライン インターフェイス (CLI) です。これは、次の 2 つの主要コンポーネントで構成されています。
- user_exp.py (設定設定ユーティリティ)
- delta_share_to_azure_panda.py (データ同期スクリプト)
前提条件
- システムにインストールされているPythonとpip。
- Procore Delta Share へのアクセス。
- MS SQL Server アカウントの資格情報。
- 会社レベルの Analytics ツールから zip パッケージをダウンロードします (Analytics > SQL Server の 「はじめに >接続> オプション 」を使用)。
- 必要な依存関係をインストールします: pip install -r requirements.txt。
- Delta Sharing プロファイル ファイル:
- Procore UI から受け取ったトークンとエンドポイントを template_config.share ファイル (ダウンロードしたコンテンツにあります) で更新し、template_config.share の名前を config.share に変更します。
- Python環境:
- Python 3.9+ と pip をシステムにインストールします。
ステップ
初期設定
- 設定ユーティリティを実行します。
Python user_exp.py
これは、次の設定に役立ちます。
- Delta Share ソースの構成
- MS SQL Server ターゲット構成
- スケジュール設定
データ同期
構成後、データ同期を実行するには次の 2 つのオプションがあります。
- 直接実行 python
delta_share_to_azure_panda.py
又は - スケジュールされた実行
セットアップ時に設定した場合、ジョブはcronスケジュールに従って自動的に実行されます。
デルタ共有の構成
- JSON 形式の Delta Share 資格情報を使用して 、config.share という名前の 新しいファイルを作成します。
{
"shareCredentialsVersion":1、
"bearerToken": "xxxxxxxxxxxxx",
"endpoint": "https://nvirginia.cloud.databricks.c...astores/xxxxxx"
}
- 必須フィールドを取得します。
メモ:これらの詳細は、Analytics Web アプリケーションから取得できます。- ShareCredentialsVersion: バージョン番号 (現在は 1)。
- BearerToken: Delta Share アクセス トークン。
- エンドポイント: Delta Share エンドポイント URL。
- ファイルを安全な場所に保存します。
- データ ソースを構成するときに、次の情報を提供するように求められます。
- テーブルのリスト (カンマ区切り)。
- すべてのテーブルを同期するには、空白のままにします。
- 例: 'table1, t able2, table3'。
- 「config.share」へのパス ファイル。
MS SQL Server の構成
次の MS SQL Server の詳細を指定する必要があります。
- データベース
- ホスト
- パスワード
- スキーマ
- ユーザー名
SSIS の構成
- コマンドラインを使用して、「 cd <path to the folder>」と入力してフォルダに移動します。
- 「pip install -r requirements.txt」または「python -m pip install -r requirements.txt」を使用して、必要なパッケージをインストールします。
- SSIS を開き、新しいプロジェクトを作成します。
- SSIS ツールボックスから、「プロセス タスクの実行」アクティビティをドラッグ アンド ドロップします。

- 「プロセスタスクの実行」をダブルクリックし、「プロセス」タブに移動します。
- 「実行可能ファイル」に、Pythonインストールフォルダ内のpython.exeへのパスを入力します。
- 「WorkingDirectory」に、実行するスクリプトが格納されているフォルダへのパスを入力します(スクリプトファイル名は含みません)。
- 「引数」に、スクリプトの名前「delta_share_to_azure_panda.py」を入力します 。 .pyで実行したい拡張して保存します。

- 上部ペインの[スタート]ボタンをクリックします。

- タスクの実行中、Python コンソールの出力が外部コンソール ウィンドウに表示されます。
- タスクが完了すると、緑色のチェックマークが表示されます。
Python ライブラリを使用して SQL Server に接続する
概要
このガイドでは、Windows オペレーティング システムで Delta Sharing 統合パッケージを設定して使用し、Analytics を使用してワークフローにデータをシームレスに統合するための詳細な手順について説明します。このパッケージは複数の実行オプションをサポートしているため、必要な構成と統合方法を選択できます。
前提条件
先に進む前に、次のものがあることを確認してください。
- アナリティクス 2.0 SKU
- Delta Sharing プロファイル ファイル:
- Procore UI から受け取ったトークンとエンドポイントを template_config.share ファイル (ダウンロードしたコンテンツにあります) で更新し、template_config.share の名前を config.share に変更します。
- Python環境:
- Python 3.9+ と pip をシステムにインストールします。
ステップ
パッケージを準備する
- JSON 形式の Delta Share 資格情報を使用して 、config.share という名前の新しいファイルを作成します。
{
"shareCredentialsVersion":1、
"bearerToken": "xxxxxxxxxxxxx",
"endpoint": "https://nvirginia.cloud.databricks.c...astores/xxxxxx"
}
- 必須フィールドを取得します。
メモ: これらの詳細は、Analytics Web アプリケーションから取得できます。- ShareCredentialsVersion: バージョン番号 (現在は 1)。
- BearerToken: Delta Share アクセス トークン。
- エンドポイント: Delta Share エンドポイント URL。
- パッケージをダウンロードして解凍します。
メモ: 圧縮されたパッケージは、会社レベルの 分析 ツールからダウンロードできます (SQL Server > Analytics >「はじめ> 接続 オプション 」を使用)。 - 任意のディレクトリにパッケージを解凍します。
- *.share Delta Sharing プロファイル ファイルをパッケージ ディレクトリにコピーして、簡単にアクセスできるようにします。

依存関係のインストール
- パッケージディレクトリでターミナルを開きます。
- 次のコマンドを実行して、依存関係をインストールします。
- pip install -r requirements.txtを実行します
コンフィギュレーションの生成
- python user_exp.py を実行して config.yaml ファイルを生成します。
このスクリプトは、必要な資格情報と設定を含む config.yaml ファイルを生成するのに役立ちます。 - データ ソースを構成するときに、次の情報を提供するように求められます。
- テーブルのリスト (カンマ区切り)。
- すべてのテーブルを同期するには、空白のままにします。
例: 'table1, table2, table3'。 - 「config.share」へのパスファイル。
- 初めて、Delta Share ソース構成の場所、テーブル、データベース、ホストなどの資格情報を指定します。
手記:その後、手動で、またはpython user_exp.pyを実行して、構成を再利用または更新できます。
cron ジョブと即時実行の構成 (オプション)
- 自動実行用にcronジョブを設定するかどうかを決定します。
- cron スケジュールを指定します。
- 形式: * * * * * ( 分、時、「月の日」、月、「曜日」)。
- 毎日午前 2 時の実行の例: 0 2 * * *
- スケジュール ログを確認するために、スケジュールが設定されるとすぐにファイル 'procore_scheduling.log' が作成されます。
また、ターミナルコマンドで実行してスケジュールを確認することもできます。
LinuxおよびMacOSの場合:
編集/削除 - 以下を使用してスケジューリングcronを編集します。
'''bash
EDITOR=nano crontab -e
```
- 上記のコマンドを実行すると、次のようなものが表示されます。
- 2 * * * * /ユーザー/your_user/スノーフレーク/venv/bin/python /ユーザー/your_user/スノーフレーク/sql_server_python/connection_config.py 2>&1 |行を読み取っている間。do echo "$(日付) - $line";完了 >> /ユーザー/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- また、schedule cron を調整したり、行全体を削除したりして、スケジュールによる実行を停止することもできます。
Windowsの場合:
- スケジュール タスクが作成されたことを確認します。
'''PowerShell
schtasks /query /tn "ProcoreDeltaShareScheduling" /fo LIST /v
``` - 編集/削除 - タスクのスケジュール設定:
タスクスケジューラを開きます。- Win + Rを押し、taskschd.mscと入力し、と入力し、Enter キーを押します。
- スケジュールされたタスクに移動します。
- 左側のウィンドウで、[タスク スケジューラ ライブラリ] を展開します。
- タスクが保存されているフォルダを探します (例: タスク スケジューラ ライブラリまたはカスタム フォルダ)。
- タスクを見つける:
- タスク名 ProcoreDeltaShareScheduling を探します。
- それをクリックすると、下部のペインに詳細が表示されます。
- スケジュールを確認します。
- [トリガー] タブをチェックして、タスクがいつ実行されるかを確認します。
- [履歴] タブをチェックして、最近の実行を確認します。
- タスクを削除するには:
- GUI からタスクを削除します。
即時実行の質問:
- 設定後すぐにデータをコピーするためのスクリプトを実行するオプション。
- config.yaml を生成した後、CLIは、パッケージに応じて、データをコピーするためのスクリプトを実行することで、いつでも個別に実行する準備ができています。以下の例を参照してください。
Python delta_share_to_azure_panda.py
又は
Python delta_share_to_SQL_spark.py
又は
パイソンdelta_share_to_azure_dfs_spark.py
実行と保守
一般的な問題と解決策
- cronジョブのセットアップ:
- システム権限が正しく設定されていることを確認します。
- ジョブの実行に失敗した場合は、システムログを確認します。
- スクリプト delta_share_to_azure_panda.pyに実行権限があることを確認します。
- 構成ファイル:
- config.yaml ファイルがスクリプトと同じディレクトリにあることを確認します。
- 変更を加える前にファイルをバックアップしてください。
サポート
さらにヘルプが必要な場合:
- スクリプト ログで詳細なエラー メッセージを確認します。
- config.yaml ファイルに設定ミスがないか再確認してください。
- 権限関連の問題については、システム管理者に問い合わせてください。
- Delta Share アクセスに関連する問題については、Procore サポートにお問い合わせください。
- 失敗したテーブルのログを確認する: failed_tables.log。
注
- 変更を加える前に、必ず構成ファイルをバックアップしてください。
- 中断を防ぐために、非運用環境で新しい構成をテストします。
Python Spark を使用して SQL Server に接続する
概要
このガイドでは、Windows オペレーティング システムで Delta Sharing 統合パッケージを設定して使用し、Analytics を使用してワークフローにデータをシームレスに統合するための詳細な手順について説明します。このパッケージは複数の実行オプションをサポートしているため、必要な構成と統合方法を選択できます。
前提条件
先に進む前に、次のものがあることを確認してください。
- アナリティクス 2.0 SKU
- Delta Sharing プロファイル ファイル:
- Procore UI から受け取ったトークンとエンドポイントを template_config.share ファイル (ダウンロードしたコンテンツにあります) で更新し、template_config.share の名前を config.share に変更します。
- Python環境:
- Python 3.9+ と pip をシステムにインストールします。
ステップ
パッケージを準備する
- JSON 形式の Delta Share 資格情報を使用して 、config.share という名前の新しいファイルを作成します。
{
"shareCredentialsVersion":1、
"bearerToken": "xxxxxxxxxxxxx",
"endpoint": "https://nvirginia.cloud.databricks.c...astores/xxxxxx"
}
- 必須フィールドを取得します。
メモ: これらの詳細は、Analytics Web アプリケーションから取得できます。- ShareCredentialsVersion: バージョン番号 (現在は 1)。
- BearerToken: Delta Share アクセス トークン。
- エンドポイント: Delta Share エンドポイント URL。
- パッケージをダウンロードして解凍します。
メモ:圧縮されたパッケージは、会社レベルの分析ツールからダウンロードできます (Analytics > SQL Server の「はじめに >> 接続オプション」を使用)。 - 任意のディレクトリにパッケージを解凍します。
- *.share Delta Sharing プロファイル ファイルをパッケージ ディレクトリにコピーして、簡単にアクセスできるようにします。
依存関係のインストール
- パッケージディレクトリでターミナルを開きます。
- 次のコマンドを実行して、依存関係をインストールします。
- pip install -r requirements.txtを実行します
コンフィギュレーションの生成
- python user_exp.py を実行して config.yaml ファイルを生成します。
このスクリプトは、必要な資格情報と設定を含む config.yaml ファイルを生成するのに役立ちます。 - データ ソースを構成するときに、次の情報を提供するように求められます。
- テーブルのリスト (カンマ区切り)。
- すべてのテーブルを同期するには、空白のままにします。
例: 'table1, table2, table3'。 - 「config.share」へのパスファイル。
- 初めて、Delta Share ソース構成の場所、テーブル、データベース、ホストなどの資格情報を指定します。
手記:その後、手動で、またはpython user_exp.pyを実行して、構成を再利用または更新できます。
cron ジョブと即時実行の構成 (オプション)
- 自動実行用にcronジョブを設定するかどうかを決定します。
- cron スケジュールを指定します。
- 形式: * * * * * ( 分、時、「月の日」、月、「曜日」)。
- 毎日午前 2 時の実行の例: 0 2 * * *
- スケジュール ログを確認するために、スケジュールが設定されるとすぐにファイル 'procore_scheduling.log' が作成されます。
また、ターミナルコマンドで実行してスケジュールを確認することもできます。
LinuxおよびMacOSの場合:
編集/削除 - 以下を使用してスケジューリングcronを編集します。
'''bash
EDITOR=nano crontab -e
```
- 上記のコマンドを実行すると、次のようなものが表示されます。
- 2 * * * * /ユーザー/your_user/スノーフレーク/venv/bin/python /ユーザー/your_user/スノーフレーク/sql_server_python/connection_config.py 2>&1 |行を読み取っている間。do echo "$(日付) - $line";完了 >> /ユーザー/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- また、schedule cron を調整したり、行全体を削除したりして、スケジュールによる実行を停止することもできます。
Windowsの場合:
- スケジュール タスクが作成されたことを確認します。
'''PowerShell
schtasks /query /tn "ProcoreDeltaShareScheduling" /fo LIST /v
``` - 編集/削除 - タスクのスケジュール設定:
タスクスケジューラを開きます。- Win + Rを押し、taskschd.mscと入力し、と入力し、Enter キーを押します。
- スケジュールされたタスクに移動します。
- 左側のウィンドウで、[タスク スケジューラ ライブラリ] を展開します。
- タスクが保存されているフォルダを探します (例: タスク スケジューラ ライブラリまたはカスタム フォルダ)。
- タスクを見つける:
- タスク名 ProcoreDeltaShareScheduling を探します。
- それをクリックすると、下部のペインに詳細が表示されます。
- スケジュールを確認します。
- [トリガー] タブをチェックして、タスクがいつ実行されるかを確認します。
- [履歴] タブをチェックして、最近の実行を確認します。
- タスクを削除するには:
- GUI からタスクを削除します。
即時実行の質問:
- 設定後すぐにデータをコピーするためのスクリプトを実行するオプション。
- config.yaml を生成した後、CLIは、パッケージに応じて、データをコピーするためのスクリプトを実行することで、いつでも個別に実行する準備ができています。以下の例を参照してください。
Python delta_share_to_azure_panda.py
又は
Python delta_share_to_SQL_spark.py
又は
パイソンdelta_share_to_azure_dfs_spark.py
実行と保守
一般的な問題と解決策
- cronジョブのセットアップ:
- システム権限が正しく設定されていることを確認します。
- ジョブの実行に失敗した場合は、システムログを確認します。
- スクリプト delta_share_to_azure_panda.pyに実行権限があることを確認します。
- 構成ファイル:
- config.yaml ファイルがスクリプトと同じディレクトリにあることを確認します。
- 変更を加える前にファイルをバックアップしてください。
サポート
さらにヘルプが必要な場合:
- スクリプト ログで詳細なエラー メッセージを確認します。
- config.yaml ファイルに設定ミスがないか再確認してください。
- 権限関連の問題については、システム管理者に問い合わせてください。
- Delta Share アクセスに関連する問題については、Procore サポートにお問い合わせください。
- 失敗したテーブルのログを確認する: failed_tables.log。
注
- 変更を加える前に、必ず構成ファイルをバックアップしてください。
- 中断を防ぐために、非運用環境で新しい構成をテストします。
Azure Functions を使用して ADLS に接続する
Python を使用して ADLS に接続する
概要
このガイドでは、Windows オペレーティング システムで Delta Sharing 統合パッケージを設定して使用し、Analytics を使用してワークフローにデータをシームレスに統合するための詳細な手順について説明します。このパッケージは複数の実行オプションをサポートしているため、必要な構成と統合方法を選択できます。
前提 条件
先に進む前に、次のものがあることを確認してください。
- アナリティクス 2.0 SKU
- Delta Sharing プロファイル ファイル:
- Procore UI から受け取ったトークンとエンドポイントを template_config.share ファイル (ダウンロードしたコンテンツにあります) で更新し、template_config.share の名前を config.share に変更します。
- Python環境:
- Python 3.9+ と pip をシステムにインストールします。
ステップス
パッケージを準備する
- JSON 形式の Delta Share 資格情報を使用して 、config.share という名前の新しいファイルを作成します。
{
"shareCredentialsVersion":1、
"bearerToken": "xxxxxxxxxxxxx",
"endpoint": "https://nvirginia.cloud.databricks.c...astores/xxxxxx"
}
- 必須フィールドを取得します。
メモ: これらの詳細は、Analytics Web アプリケーションから取得できます。- ShareCredentialsVersion: バージョン番号 (現在は 1)。
- BearerToken: Delta Share アクセス トークン。
- エンドポイント: Delta Share エンドポイント URL。
- パッケージをダウンロードして解凍します。
メモ:zip パッケージは、会社レベルの分析ツールからダウンロードできます (Analytics > Azure の「はじめに>>接続オプション」を使用)。 - 任意のディレクトリにパッケージを解凍します。
- *.share Delta Sharing プロファイル ファイルをパッケージ ディレクトリにコピーして、簡単にアクセスできるようにします。
依存関係のインストール
- パッケージディレクトリでターミナルを開きます。
- 次のコマンドを実行して、依存関係をインストールします。
- pip install -r requirements.txtを実行します
コンフィギュレーションの生成
- python user_exp.py を実行して config.yaml ファイルを生成します。
このスクリプトは、必要な資格情報と設定を含む config.yaml ファイルを生成するのに役立ちます。 - データ ソースを構成するときに、次の情報を提供するように求められます。
- テーブルのリスト (カンマ区切り)。
- すべてのテーブルを同期するには、空白のままにします。
例: 'table1, table2, table3'。 - 「config.share」へのパスファイル。
- 初めて、Delta Share ソース構成の場所、テーブル、データベース、ホストなどの資格情報を指定します。
メモ:その後、手動で、またはpython user_exp.pyを実行して、構成を再利用または更新できます。
cron ジョブと即時実行の構成 (オプション)
- 自動実行用にcronジョブを設定するかどうかを決定します。
- cron スケジュールを指定します。
- 形式: * * * * * ( 分、時、「月の日」、月、「曜日」)。
- 毎日午前 2 時の実行の例: 0 2 * * *
- スケジュール ログを確認するために、スケジュールが設定されるとすぐにファイル 'procore_scheduling.log' が作成されます。
また、ターミナルコマンドで実行してスケジュールを確認することもできます。
LinuxおよびMacOSの場合:
編集/削除 - 以下を使用してスケジューリングcronを編集します。
'''bash
EDITOR=nano crontab -e
```
- 上記のコマンドを実行すると、次のようなものが表示されます。
- 2 * * * * /ユーザー/your_user/スノーフレーク/venv/bin/python /ユーザー/your_user/スノーフレーク/sql_server_python/connection_config.py 2>&1 |行を読み取っている間。do echo "$(日付) - $line";完了 >> /ユーザー/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- また、schedule cron を調整したり、行全体を削除したりして、スケジュールによる実行を停止することもできます。
Windowsの場合:
- スケジュール タスクが作成されたことを確認します。
'''PowerShell
schtasks /query /tn "ProcoreDeltaShareScheduling" /fo LIST /v
``` - 編集/削除 - タスクのスケジュール設定:
タスクスケジューラを開きます。- Win + Rを押し、taskschd.mscと入力し、と入力し、Enter キーを押します。
- スケジュールされたタスクに移動します。
- 左側のウィンドウで、[タスク スケジューラ ライブラリ] を展開します。
- タスクが保存されているフォルダを探します (例: タスク スケジューラ ライブラリまたはカスタム フォルダ)。
- タスクを見つける:
- タスク名 ProcoreDeltaShareScheduling を探します。
- それをクリックすると、下部のペインに詳細が表示されます。
- スケジュールを確認します。
- [トリガー] タブをチェックして、タスクがいつ実行されるかを確認します。
- [履歴] タブをチェックして、最近の実行を確認します。
- タスクを削除するには:
- GUI からタスクを削除します。
即時実行の質問:
- 設定後すぐにデータをコピーするためのスクリプトを実行するオプション。
- config.yaml を生成した後、CLIは、パッケージに応じて、データをコピーするためのスクリプトを実行することで、いつでも個別に実行する準備ができています。以下の例を参照してください。
Python delta_share_to_azure_panda.py
または
Python delta_share_to_SQL_spark.py
または
パイソンdelta_share_to_azure_dfs_spark.py
実行と保守
一般的な問題と解決策
- cronジョブのセットアップ:
- システム権限が正しく設定されていることを確認します。
- ジョブの実行に失敗した場合は、システムログを確認します。
- スクリプト delta_share_to_azure_panda.pyに実行権限があることを確認します。
- 構成ファイル:
- config.yaml ファイルがスクリプトと同じディレクトリにあることを確認します。
- 変更を加える前にファイルをバックアップしてください。
サポート
さらにヘルプが必要な場合:
- スクリプト ログで詳細なエラー メッセージを確認します。
- config.yaml ファイルに設定ミスがないか再確認してください。
- 権限関連の問題については、システム管理者に問い合わせてください。
- Delta Share アクセスに関連する問題については、Procore サポートにお問い合わせください。
- 失敗したテーブルのログを確認する: failed_tables.log。
注
- 変更を加える前に、必ず構成ファイルをバックアップしてください。
- 中断を防ぐために、非運用環境で新しい構成をテストします。
Spark を使用した ADLS への接続
概要
このガイドでは、Windows オペレーティング システムで Delta Sharing 統合パッケージを設定して使用し、Analytics を使用してワークフローにデータをシームレスに統合するための詳細な手順について説明します。このパッケージは複数の実行オプションをサポートしているため、必要な構成と統合方法を選択できます。
前提 条件
先に進む前に、次のものがあることを確認してください。
- アナリティクス 2.0 SKU
- Delta Sharing プロファイル ファイル:
- Procore UI から受け取ったトークンとエンドポイントを template_config.share ファイル (ダウンロードしたコンテンツにあります) で更新し、template_config.share の名前を config.share に変更します。
- Python環境:
- Python 3.9+ と pip をシステムにインストールします。
ステップス
パッケージを準備する
- JSON 形式の Delta Share 資格情報を使用して 、config.share という名前の新しいファイルを作成します。
{
"shareCredentialsVersion":1、
"bearerToken": "xxxxxxxxxxxxx",
"endpoint": "https://nvirginia.cloud.databricks.c...astores/xxxxxx"
}
- 必須フィールドを取得します。
メモ: これらの詳細は、Analytics Web アプリケーションから取得できます。- ShareCredentialsVersion: バージョン番号 (現在は 1)。
- BearerToken: Delta Share アクセス トークン。
- エンドポイント: Delta Share エンドポイント URL。
- パッケージをダウンロードして解凍します。
メモ:zip パッケージは、会社レベルの分析ツールからダウンロードできます (Analytics > Azure >>接続オプションの概要を使用)。 - 任意のディレクトリにパッケージを解凍します。
- *.share Delta Sharing プロファイル ファイルをパッケージ ディレクトリにコピーして、簡単にアクセスできるようにします。
依存関係のインストール
- パッケージディレクトリでターミナルを開きます。
- 次のコマンドを実行して、依存関係をインストールします。
- pip install -r requirements.txtを実行します
コンフィギュレーションの生成
- python user_exp.py を実行して config.yaml ファイルを生成します。
このスクリプトは、必要な資格情報と設定を含む config.yaml ファイルを生成するのに役立ちます。 - データ ソースを構成するときに、次の情報を提供するように求められます。
- テーブルのリスト (カンマ区切り)。
- すべてのテーブルを同期するには、空白のままにします。
例: 'table1, table2, table3'。 - 「config.share」へのパスファイル。
- 初めて、Delta Share ソース構成の場所、テーブル、データベース、ホストなどの資格情報を指定します。
メモ:その後、手動で、またはpython user_exp.pyを実行して、構成を再利用または更新できます。
cron ジョブと即時実行の構成 (オプション)
- 自動実行用にcronジョブを設定するかどうかを決定します。
- cron スケジュールを指定します。
- 形式: * * * * * ( 分、時、「月の日」、月、「曜日」)。
- 毎日午前 2 時の実行の例: 0 2 * * *
- スケジュール ログを確認するために、スケジュールが設定されるとすぐにファイル 'procore_scheduling.log' が作成されます。
また、ターミナルコマンドで実行してスケジュールを確認することもできます。
LinuxおよびMacOSの場合:
編集/削除 - 以下を使用してスケジューリングcronを編集します。
'''bash
EDITOR=nano crontab -e
```
- 上記のコマンドを実行すると、次のようなものが表示されます。
- 2 * * * * /ユーザー/your_user/スノーフレーク/venv/bin/python /ユーザー/your_user/スノーフレーク/sql_server_python/connection_config.py 2>&1 |行を読み取っている間。do echo "$(日付) - $line";完了 >> /ユーザー/your_user/snowflake/sql_server_python/procore_scheduling.log # procore-data-import
- また、schedule cron を調整したり、行全体を削除したりして、スケジュールによる実行を停止することもできます。
Windowsの場合:
- スケジュール タスクが作成されたことを確認します。
'''PowerShell
schtasks /query /tn "ProcoreDeltaShareScheduling" /fo LIST /v
``` - 編集/削除 - タスクのスケジュール設定:
タスクスケジューラを開きます。- Win + Rを押し、taskschd.mscと入力し、と入力し、Enter キーを押します。
- スケジュールされたタスクに移動します。
- 左側のウィンドウで、[タスク スケジューラ ライブラリ] を展開します。
- タスクが保存されているフォルダを探します (例: タスク スケジューラ ライブラリまたはカスタム フォルダ)。
- タスクを見つける:
- タスク名 ProcoreDeltaShareScheduling を探します。
- それをクリックすると、下部のペインに詳細が表示されます。
- スケジュールを確認します。
- [トリガー] タブをチェックして、タスクがいつ実行されるかを確認します。
- [履歴] タブをチェックして、最近の実行を確認します。
- タスクを削除するには:
- GUI からタスクを削除します。
即時実行の質問:
- 設定後すぐにデータをコピーするためのスクリプトを実行するオプション。
- config.yaml を生成した後、CLIは、パッケージに応じて、データをコピーするためのスクリプトを実行することで、いつでも個別に実行する準備ができています。以下の例を参照してください。
Python delta_share_to_azure_panda.py
または
Python delta_share_to_SQL_spark.py
または
パイソンdelta_share_to_azure_dfs_spark.py
実行と保守
一般的な問題と解決策
- cronジョブのセットアップ:
- システム権限が正しく設定されていることを確認します。
- ジョブの実行に失敗した場合は、システムログを確認します。
- スクリプト delta_share_to_azure_panda.pyに実行権限があることを確認します。
- 構成ファイル:
- config.yaml ファイルがスクリプトと同じディレクトリにあることを確認します。
- 変更を加える前にファイルをバックアップしてください。
サポート
さらにヘルプが必要な場合:
- スクリプト ログで詳細なエラー メッセージを確認します。
- config.yaml ファイルに設定ミスがないか再確認してください。
- 権限関連の問題については、システム管理者に問い合わせてください。
- Delta Share アクセスに関連する問題については、Procore サポートにお問い合わせください。
- 失敗したテーブルのログを確認する: failed_tables.log。
注
- 変更を加える前に、必ず構成ファイルをバックアップしてください。
- 中断を防ぐために、非運用環境で新しい構成をテストします。
Data Factory を使用して Fabric Lakehouse に接続する
概要
Delta Sharing と Microsoft Fabric Data Factory を統合すると、Analytics 2.0 を使用した分析ワークフローで共有 Delta テーブルにシームレスにアクセスして処理できます。Delta Sharingは、安全なデータコラボレーションのためのオープンプロトコルであり、組織が重複することなくデータを共有できるようにします。
前提条件
- アナリティクス 2.0 SKU
- Delta Sharing 資格情報:
- データ プロバイダーから share.json (または同等の) Delta Sharing 資格情報 ファイルを取得します。
- このファイルには、次のものが含まれている必要があります。
- エンドポイント URL: Delta Sharing Server の URL。
- ベアラートークン: 安全なデータアクセスに使用されます。
- Microsoft ファブリックのセットアップ:
- アクティブなサブスクリプションを持つMicrosoft Fabricテナント アカウント。
- Microsoft Fabric 対応ワークスペースへのアクセス。
ステップ
Data Factory エクスペリエンスに切り替える
- Microsoft Fabric ワークスペースに移動します。
- [ 新規] を選択し、[ Dataflow Gen2] を選択します。
データフローの設定
- データフローエディターに移動します。
- [ データを取得する ] をクリックし、[ その他] を選択します。
- [新しいソース] で、データ ソースとして [Delta Sharing Other] を選択します。

- 次の詳細を入力します。
- URL: Delta Sharing 構成ファイルから。
- ベアラー トークン: config.share ファイルにあります。

- [ 次へ ] をクリックし、目的のテーブルを選択します。
- [ 作成 ] をクリックしてセットアップを完了します。
データ変換の実行
データフローを設定したら、共有デルタデータに変換を適用できるようになりました。以下のリストから [Delta Sharing Data] オプションを選択します。
- データ送信先を追加
- レイクハウスを作成/開く
データ送信先を追加
- Data Factory に移動します。
- [Add Data Destination] をクリックします。
- ターゲットとして 「Lakehouse 」を選択し、「 次へ」をクリックします。
- 宛先ターゲットを選択し、[ 次へ] をクリックして確定します。
レイクハウスの作成-オープン
- レイクハウスを作成して開き、[データを取得する]をクリックします。
- [新しいデータフロー Gen2] を選択します。
- [ データの取得]、[ その他 ] の順にクリックして、[ Delta Sharing] を見つけます。
- config.share ファイルから URL ベアラー トークンを入力し、 [ Next] を選択します。
- ダウンロードするデータ/テーブルを選択し、[次へ] をクリックします。
- これらの操作の後、選択したすべてのデータが Fabric Lakehouse にあるはずです。
検証と監視
データパイプラインとフローをテストして、円滑な実行を確保します。データ内で監視ツールを使用する
各アクティビティの進行状況とログを追跡するファクトリ。
Fabric ノートブックを使用した Fabric Lakehouse への接続
概要
Microsoft ファブリックで Data Factory を Delta Sharing と共に使用すると、Analytics 2.0 での分析ワークフローの一部として、共有 Delta テーブルのシームレスな統合と処理が可能になります。Delta Sharing は、安全なデータ共有のためのオープン プロトコルであり、データを複製することなく組織間のコラボレーションを可能にします。
このガイドでは、Delta Sharing を使用して Fabric で Data Factory を設定して使用し、ノートブックを使用してデータを処理してレイクハウスにエクスポートする手順について説明します。
前提条件
- アナリティクス 2.0 SKU
- Delta Sharing 資格情報:
- データ プロバイダーによって提供される Delta Sharing 資格情報へのアクセス。
- 共有プロファイル ファイル (config.share)含有:
- エンドポイント URL (Delta Sharing Server URL)。
- アクセストークン(安全なデータアクセスのためのベアラートークン)。
- 以下のテンプレートを使用して、特定の認証情報で config.yaml ファイルを作成します。
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Microsoftファブリック環境:
- アクティブなサブスクリプションを持つMicrosoft Fabricテナント アカウント。
- ファブリック対応のワークスペース。
- パッケージとスクリプト:
- fabric-lakehouse パッケージをダウンロードします。ディレクトリには次のものが含まれている必要があります。
- ds_to_lakehouse.py:ノートブック コード。
- readme.md:指示。
メモ:圧縮されたパッケージは、会社レベルの分析ツールからダウンロードできます (Analytics > Azure >>接続オプションの概要を使用)。
- fabric-lakehouse パッケージをダウンロードします。ディレクトリには次のものが含まれている必要があります。
ステップ
構成のセットアップ
- config.yaml を作成します ファイルを作成し、次の構造で構成を定義します
source_config:
config_path: path/to/your/delta-sharing-credentials-file.share
tables: # オプション - すべてのテーブルを処理するには空のままにします
- table_name1
- table_name2
target_config:
lakehouse_path: path/to/your/fabric/lakehouse/tables/ # ファブリックのレイクハウスへのパス
レイクハウスをセットアップする
- Microsoft Fabric ワークスペースを開きます。
- Lakehouse に移動し、[ ノートブックを開く]、[ 新しいノートブック] の順にクリックします。
- config.yaml#lakehouse_pathの値がわからない場合は、画面からコピーできます。
- [ファイル] の省略記号をクリックし、[ABFS パスのコピー] を選択します。



3. ds_to_lakehouse.py のコードをコピーしてノートブックウィンドウに貼り付けます(Pyspark Python)。

次のステップは、独自のconfig.yamlとconfig.shareをLakehouseの Resources フォルダーにアップロードすることです。独自のディレクトリを作成するか、組み込み ディレクトリ( Lakehouseによってリソース用にすでに作成されています)を使用できます。


以下の例は、 config.yaml ファイルの標準 の組み込み ディレクトリを示しています。
注: 両方のファイルを同じレベルにアップロードし、 プロパティ config_pathにアップロードしてください。

4. ノートブックのコード、170 行目から 175 行目を確認します。
以下の例は、必要な行の変更を示しています。
config_path = "./env/config.yaml"
宛先
config_path = "./builtin/config.yaml"
ファイルはカスタム環境ではなく組み込みフォルダーにあるため、ファイルの独自の構造を必ず監視してください。別のフォルダーにアップロードすることもできますが、そのような場合は、ノートブックのコードを更新して config.yaml ファイルを正しく見つけてください。

5. [セルの実行]をクリックします。

検証
- ジョブが完了したら、データがレイクハウスに正常にコピーされたことを確認します。
- 指定したテーブルを確認し、データが共有 Delta テーブルと一致することを確認します。
- ジョブが終了するまで待つと、すべてのデータがコピーされます。
Azure Functions を使用して SQL Server に接続する
Data Factory を使用した SQL Server への接続
概要
このドキュメントでは、Delta Share から SQL ウェアハウスにデータを転送するために Microsoft Fabric でデータ パイプラインを設定する手順について説明します。この構成により、Delta Lake ソースと SQL 宛先間のシームレスなデータ統合が可能になります。
前提条件
- 適切なアクセス許可を持つアクティブな Microsoft ファブリック アカウント。
- Delta Share の資格情報。
- SQL ウェアハウスの資格情報。
- ファブリック内のデータ フロー Gen2 へのアクセス。
ステップ
Access Data Flow Gen2
- Microsoft Fabricアカウントにログインします。
- ワークスペースに移動します。
- 使用可能なオプションから [データ フロー Gen2] を選択します。
データ・ソースの構成
- 「別のソースからのデータ」をクリックして設定を開始します。
- [データの取得] 画面で、次の操作を行います。
- [データ ソースの選択] というラベルの付いた検索バーを見つけます。
- 検索フィールドに「差分共有」と入力します。
- 結果から [Delta Sharing] を選択します。
デルタ共有接続の設定
- プロンプトが表示されたら、Delta Share の認証情報を入力します。
- すべての必須フィールドに正確に入力されていることを確認します。
- 可能であれば、接続を検証します。
- 「次へ」をクリックして次に進みます。
- 使用可能なテーブルのリストを確認します。
- アクセスできるすべてのテーブルが表示されます。
- 転送するテーブルを選択します。
データ送信先の構成
- 「Add Data Destination」をクリックします。
- 宛先として [SQL ウェアハウス] を選択します。
- SQL 資格情報を入力します。
- サーバーの詳細。
- 認証情報。
- データベースの仕様。
- 接続設定を確認します。
ファイナライズとデプロイ
- すべての構成を確認します。
- [公開] をクリックしてデータ フローをデプロイします。
- 確認メッセージが表示されるのを待ちます。
検証
- SQL ウェアハウスにアクセスします。
- データが使用可能であり、適切に構造化されていることを確認します。
- テスト クエリを実行して、データの整合性を確認します。
トラブルシューティング
一般的な問題と解決策:
- 接続エラー: 資格情報とネットワーク接続を確認します。
- 不足しているテーブル: 差分共有のアクセス許可を確認します。
- パフォーマンスの問題: リソースの割り当てと最適化の設定を確認します。
Fabric Notebook を使用した SQL Server への接続
概要
Microsoft ファブリックで Data Factory を Delta Sharing と共に使用すると、Analytics 2.0 での分析ワークフローの一部として、共有 Delta テーブルのシームレスな統合と処理が可能になります。Delta Sharing は、安全なデータ共有のためのオープン プロトコルであり、データを複製することなく組織間のコラボレーションを可能にします。
このガイドでは、Delta Sharing を使用して Fabric で Data Factory を設定して使用し、ノートブックを使用してデータを処理してレイクハウスにエクスポートする手順について説明します。
前提条件
- アナリティクス 2.0 SKU
- Delta Sharing 資格情報:
- データ プロバイダーによって提供される Delta Sharing 資格情報へのアクセス。
- 共有プロファイル ファイル (config.share)含有:
- エンドポイント URL (Delta Sharing Server URL)。
- アクセストークン(安全なデータアクセスのためのベアラートークン)。
- 以下のテンプレートを使用して、特定の認証情報で config.yaml ファイルを作成します。
{
"shareCredentialsVersion": 1,
"endpoint": "your-delta-sharing-server-url",
"bearerToken": "your-master-token"
}
- Microsoftファブリック環境:
- アクティブなサブスクリプションを持つMicrosoft Fabricテナント アカウント。
- ファブリック対応のワークスペース。
- パッケージとスクリプト:
- fabric-lakehouse パッケージをダウンロードします。ディレクトリには次のものが含まれている必要があります。
- ds_to_lakehouse.py:ノートブック コード。
- readme.md:指示。
メモ:圧縮されたパッケージは、会社レベルの分析ツールからダウンロードできます (Analytics > Azure >>接続オプションの概要を使用)。
- fabric-lakehouse パッケージをダウンロードします。ディレクトリには次のものが含まれている必要があります。
ステップ
構成のセットアップ
- config.yaml を作成します ファイルを作成し、次の構造で構成を定義します
source_config:
config_path: path/to/your/delta-sharing-credentials-file.share
tables: # オプション - すべてのテーブルを処理するには空のままにします
- table_name1
- table_name2
target_config:
lakehouse_path: path/to/your/fabric/lakehouse/tables/ # ファブリックのレイクハウスへのパス
レイクハウスをセットアップする
- Microsoft Fabric ワークスペースを開きます。
- Lakehouse に移動し、[ ノートブックを開く]、[ 新しいノートブック] の順にクリックします。
- config.yaml#lakehouse_pathの値がわからない場合は、画面からコピーできます。
- [ファイル] の省略記号をクリックし、[ABFS パスのコピー] を選択します。
3. ds_to_lakehouse.py のコードをコピーしてノートブックウィンドウに貼り付けます(Pyspark Python)。
次のステップは、独自のconfig.yamlとconfig.shareをLakehouseの Resources フォルダーにアップロードすることです。独自のディレクトリを作成するか、組み込み ディレクトリ( Lakehouseによってリソース用にすでに作成されています)を使用できます。
以下の例は、 config.yaml ファイルの標準 の組み込み ディレクトリを示しています。
注: 両方のファイルを同じレベルにアップロードし、 プロパティ config_pathにアップロードしてください。
4. ノートブックのコード、170 行目から 175 行目を確認します。
以下の例は、必要な行の変更を示しています。
config_path = "./env/config.yaml"
宛先
config_path = "./builtin/config.yaml"
ファイルはカスタム環境ではなく組み込みフォルダーにあるため、ファイルの独自の構造を必ず監視してください。別のフォルダーにアップロードすることもできますが、そのような場合は、ノートブックのコードを更新して config.yaml ファイルを正しく見つけてください。
5. [セルの実行]をクリックします。
検証
- ジョブが完了したら、データがレイクハウスに正常にコピーされたことを確認します。
- 指定したテーブルを確認し、データが共有 Delta テーブルと一致することを確認します。
- ジョブが終了するまで待つと、すべてのデータがコピーされます。
Databricks に接続する
注
この接続方法は、通常、データの専門家によって使用されます。- Databricks 環境にログインします。
- [カタログ] セクションに移動します。
- トップ メニューから [Delta Sharing] を選択します。
- [ 自分と共有] を選択します。
- 提供された 共有識別子をコピーします。
- Procore で、ナビゲーション バーの右上にある [ アカウントとプロファイル] アイコンをクリックします。
- [マイ プロファイル設定] をクリックします。
- [分析] タブをクリックします。
- Databricks 共有識別子を入力します。
- [接続] をクリックします。
メモ:共有識別子が Procore のシステムに追加されると、Procore Databricks 接続が Databricks 環境の [プロバイダー] の下の [自分と共有] タブに表示されます。データが表示されるまでに最大 24 時間かかる場合があります。
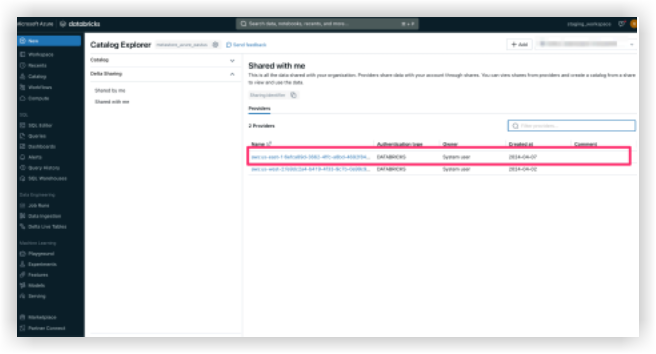
- Procore Databricks 接続が [自分と共有 ] タブに表示されるようになったら、[Procore 識別子] を選択し、[カタログの作成] をクリックします。
- 共有カタログの任意の名前を入力し、[ 作成] をクリックします。
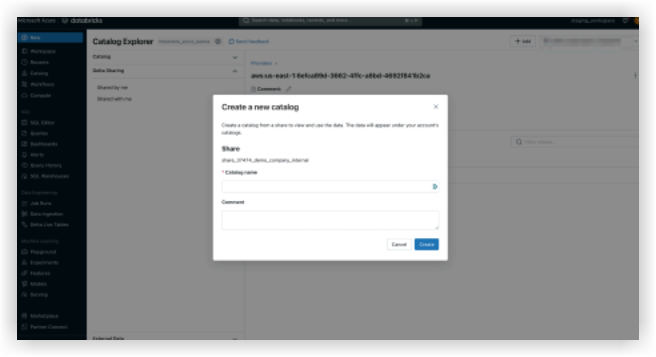
- 共有カタログとテーブルは、指定された名前で 「カタログエクスプローラ」(Catalog Explorer)

メモ:ご質問やサポートが必要な場合は、Procore サポートまでご連絡ください。
Pythonを使用したSnowflakeへの接続
Python を使用して Amazon S3 に接続する
独自の接続を構築する
BigQuery に接続する
Exponam を使用して Microsoft Excel に接続する
概要
このガイドでは、Exponam.Connect アドインを使用して Delta Share から Microsoft Excel に Analytics データを直接インポートする手順について説明します。
このメソッドを使用すると、次のことが可能になります。
-
CSV を手動でダウンロードすることなく、Excel で Procore データに直接アクセスできます。
-
インポートする前に特定の列をフィルタリングして選択し、必要なデータのみを読み込むようにします。
-
他の方法では処理が遅すぎる可能性のある大規模なデータセットを操作します。
前提 条件
-
Delta Share 資格情報。Delta Sharing 資格情報を含む config.share ファイルへのアクセス。
-
ライセンス:
-
Exponam.Connect Free: 100 行のデータのインポートに制限されています。
-
Exponam.Connect Pro: 大規模なデータセット (最大 100 万 + 行) をインポートする場合に必要です。
-
Exponam アドインのインストール
-
Exponam.Connect をダウンロードするオペレーティングシステム(WindowsまたはMac)のインストーラー。
-
インストーラーファイルを実行し、画面の指示に従います。
-
インストールが完了したら、 Microsoft Excel を起動し、新しいブックを開きます。
デルタ共有接続の初期化
-
Microsoft Excel で、[ Exponam Pro ] タブに移動します。
![Analytics - Exponam を使用して Microsoft Excel に接続する - [Exponam Pro] タブ](https://images.ctfassets.net/plvbd9i6qkpm/5ajYupsHOL4NB7DxfSgScq/8a9309e9da0f4ab9913cdd6f33f76288/Analytics_-_Connect_to_Microsoft_Excel_Using_Exponam_-_Exponam_Pro_tab.png?fm=webp)
-
[ データのインポート] をクリックします。
-
[Delta Share] アイコンをクリックします。
![Analytics - Exponam を使用して Microsoft Excel に接続 - [データのインポート] ボタンと Delta Share アイコン](https://images.ctfassets.net/plvbd9i6qkpm/lFD9q6ZDpTwtoK2sOKyxy/d22b4b862199c073cb8476dca17e406a/Analytics_-_Connect_to_Microsoft_Excel_Using_Exponam_-_Import_data_button___Delta_Share_icon.png?fm=webp)
-
config.share ファイルを見つけて選択します。
-
「 開く」をクリックします。
データの選択とフィルタリング
Exponam インターフェイスに、使用可能なすべてのデータ テーブルの一覧が表示されます。
-
アクセスしたいテーブルの名前をクリックします。
-
Excel にインポートする前に、Exponam インターフェイスを使用してデータを絞り込みます。たとえば、フィルターを適用したり、特定の列を選択したりできます。
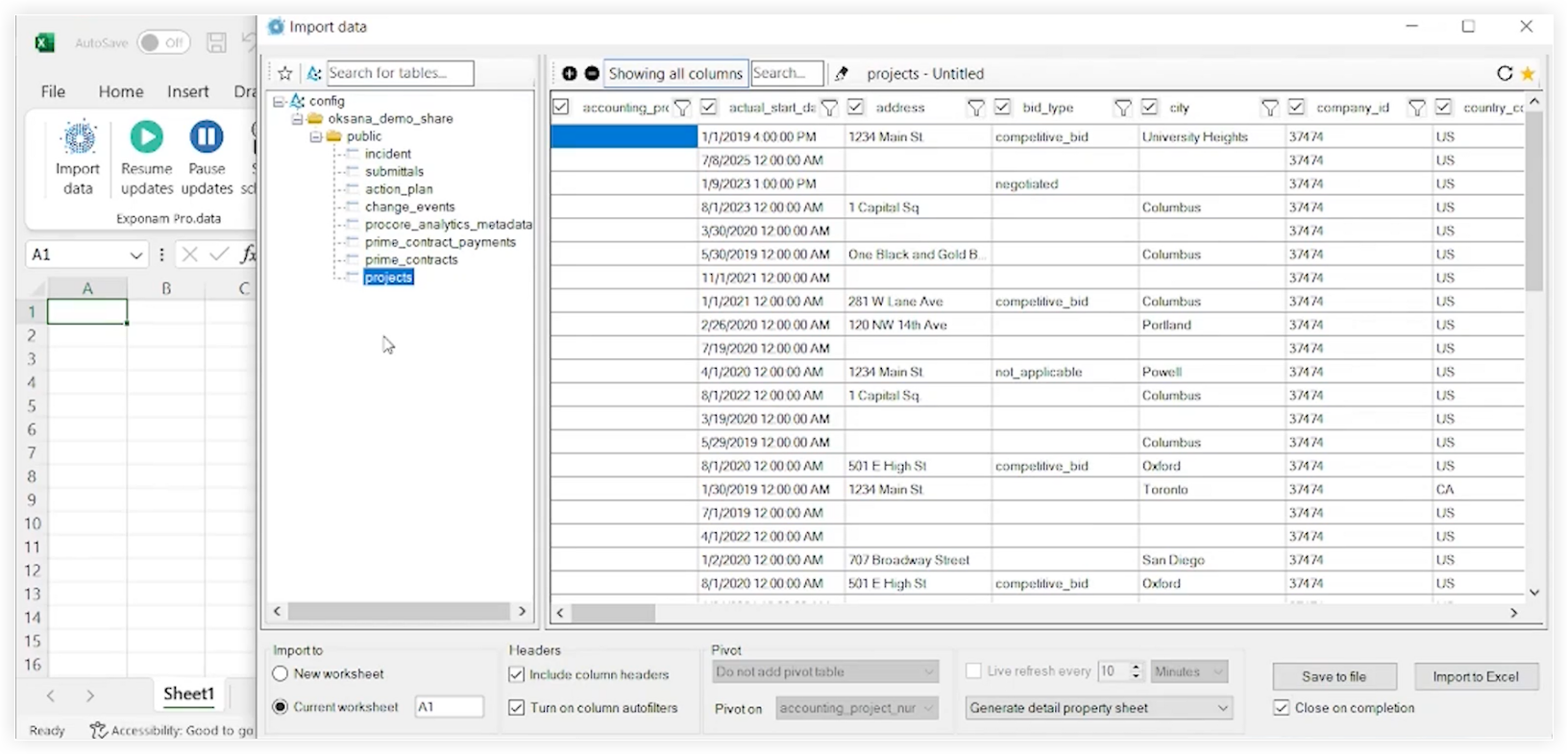
Excel にインポート
-
構成と行数を確認します。
メモ: 行数がライセンス制限内であることを確認してください。 -
[ Excel にインポート] をクリックします。
データは、アクティブな Excel ワークシートに入力されます。
検証
-
Excel の列と行が [Exponam] ウィンドウで選択したものと一致していることを確認します。
-
データ型 (日付、通貨など) の形式が正しいことを確認します。
トラブルシューティング
-
「ExponamPro」タブがありません。インストールが成功したことを確認し、Excelの「アドイン」設定をチェックして有効になっていることを確認します。
-
接続エラー。config.share ファイルがまだ有効であり、アクティブなインターネット接続があることを確認します。
-
行数制限に達しました。100行しか表示されない場合は、Exponam設定でライセンスステータスを確認してください。